Reading excel file in pyspark (Databricks notebook)
This blog we will learn how to read excel file in pyspark (Databricks = DB , Azure = Az).
Most of the people have read CSV file as source in Spark implementation and even spark provide direct support to read CSV file but as I was required to read excel file since my source provider was stringent with not providing the CSV I had the task to find a solution how to read data from excel file and to increase my difficulty I had to read from different sheets of the same excel file.
After searching on google I couldn’t find any direct answers but so thought of writing this blog so that people who want to read the Excel file in spark (Python) can read this blog and do it quickly.
So I will be explaining step wise on how to read excel file in pyspark (DB Az).
Library required for reading excel file is “crealytics/spark-excel” this library saved me lots of time to read excel and made my life happier kudos to the developers and contributors. This is an active community which is managing this plugin.
You might find it strange but the GIT page shows sample of code in Scala and all the documentation is for Scala and not a single line of code for pyspark, but I tried my luck and it worked for me in pyspark.
This library requires Spark 2.0+
You can link against this library in your program at the following coordinates:
Scala 2.12
groupId: com.crealytics
artifactId: spark-excel_2.12
version: 0.13.1Scala 2.11
groupId: com.crealytics
artifactId: spark-excel_2.11
version: 0.13.1Install library in DB cluster in Az.
- Go to clusters in DB workspace and click on the cluster you want to install the library on, once you click on the cluster name you will land on cluster details page, switch to Libraries tab and click on “Install New”.

- 1 After clicking install library, you will get pop up window were you need to click on Maven and give the following co-ordinates.
com.crealytics:spark-excel_2.12:0.13.5
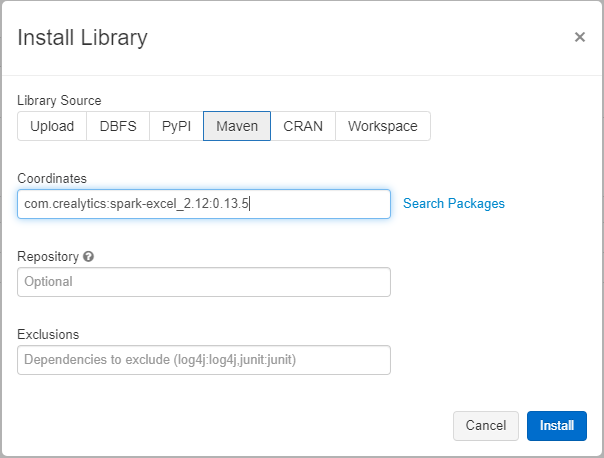
Or if you want you can click on Search Packages and pop up window will open named “Search Packages”. From dropdown select “Maven Central” and type “com.crealytics” in the text search box and select latest version of the plugin or as per your scala version in Cluster on DB Az. I am going with “spark-excel_2.12” as per my scala version on cluster. As you click on select it will populate the co-ordinates as show in the above screenshot and then click install.

Once your library is install you it will be shown as below.

We are all set to start writing our code to read data from excel file.
2. Code in DB notebook for reading excel file.
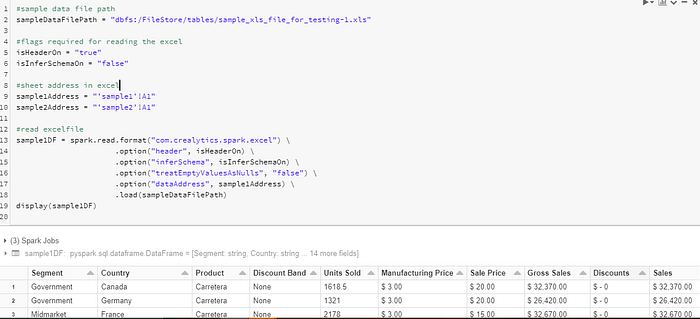
Sample Code
#sample data file path
sampleDataFilePath = “dbfs:/FileStore/tables/sample_xls_file_for_testing-1.xls”#flags required for reading the excel
isHeaderOn = “true”
isInferSchemaOn = “false”#sheet address in excel
sample1Address = “‘sample1’!A1”
sample2Address = “‘sample2’!A1”#read excelfile
sample1DF = spark.read.format(“com.crealytics.spark.excel”) \
.option(“header”, isHeaderOn) \
.option(“inferSchema”, isInferSchemaOn) \
.option(“treatEmptyValuesAsNulls”, “false”) \
.option(“dataAddress”, sample1Address) \
.load(sampleDataFilePath)
display(sample1DF)
This above code will read all the data from sheet “sample1” from the sample xls file starting from cell A1 to all the columns.
You can also specify range of cells in the code, incase you want to read only specific cells.
Sample code to read for specific cell range.
#sample data file path
sampleDataFilePath = “dbfs:/FileStore/tables/sample_xls_file_for_testing-1.xls”#flags required for reading the excel
isHeaderOn = “true”
isInferSchemaOn = “false”#sheet address in excel
sample1Address = “‘sample1’!A1:P35”
sample2Address = “‘sample2’!A1:P35”#read excelfile
sample1DF = spark.read.format(“com.crealytics.spark.excel”) \
.option(“header”, isHeaderOn) \
.option(“inferSchema”, isInferSchemaOn) \
.option(“treatEmptyValuesAsNulls”, “false”) \
.option(“dataAddress”, sample1Address) \
.load(sampleDataFilePath)
display(sample1DF)
Data Addresses
As you can see in the examples above, the location of data to read or write can be specified with the dataAddress option. Currently the following address styles are supported:
B3: Start cell of the data. Reading will return all rows below and all columns to the right. Writing will start here and use as many columns and rows as required.B3:F35: Cell range of data. Reading will return only rows and columns in the specified range. Writing will start in the first cell (B3in this example) and use only the specified columns and rows. If there are more rows or columns in the DataFrame to write, they will be truncated. Make sure this is what you want.'My Sheet'!B3:F35: Same as above, but with a specific sheet.
If the sheet name is unavailable, it is possible to pass in an index:
#sheet address in excel
sample1Address = "'0'!A1"#read excelfile
sample1DF = spark.read.format("com.crealytics.spark.excel") \
.option("header", isHeaderOn) \
.option("inferSchema", isInferSchemaOn) \
.option("treatEmptyValuesAsNulls", "false") \
.option("dataAddress", sample1Address) \
.load(sampleDataFilePath)
display(sample1DF)
P.S:
Sample data downloaded from:
https://www.learningcontainer.com/sample-excel-data-for-analysis/
Biblography:
Github link in case you want to contribute
In case you don’t like to read the things, see the video tutorial to do the same.